Introduction
On Wednesday March 10th 2021, an OVH datacenter located in Strasbourg, France experienced a devastating fire destroying part of its servers and making inaccessible more than 400 000 distinct domain names.
This event reminds us in a dramatic way that the web is fragile and any content present on it can disappear at any time.
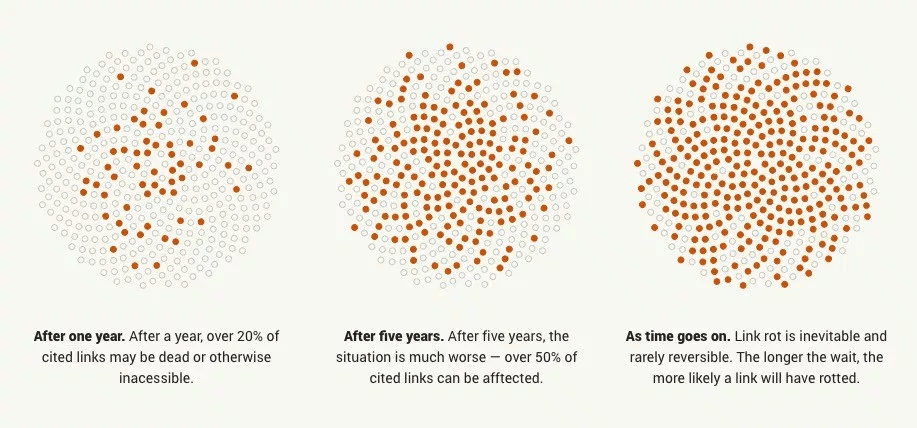
This phenomenon where a link to a document or a web page stops working is known as Link Rot.
Source: perma.cc
Link Rot can occur after a material defect as seen with the fire of the OVH datacenter, but can also be the consequence of other phenomena: bankruptcy of a company, content moderation, or even hacking.
A 2013 study analyzed nearly 15,000 links and found that the median lifespan of web pages was 9.3 years. In another rather extreme example of link rot, Ernie Smith found no working links in a book about the internet from 1994.
For any content on the web, the question is not if it will be deleted, but when.
Fortunately initiatives like archive.org (especially its Wayback Machine project) exist and archive a very large number of web pages (more than 549 billion for Wayback Machine).

Source: archive.org
We can also mention ArchiveTeam which maintains a “Deathwatch” of sites whose content is threatened to be deleted or the BnF (Bibliothèque nationale de France) whose archives represent more than 1 petabyte of data.
In addition to these initiatives, it may be interesting to create a personal archive to prevent the loss of content we consider important.
In this article, I will review three tools to archive web page content: Wallabag, Conifer and Archivebox.
The versions used at the time of the creation of this article are the following:
- Wallabag: 2.4.1
- Archivebox: 0.5.6
Wallabag
Presentation
Wallabag is a “read-it-later” service allowing to save and classify web pages to consult them later.
When you add a web page to Wallabag, it will extract the text and images of this page.
Thus, if this page becomes unavailable, it will still be possible to read it in Wallabag.

Source: wallabag.org
Wallabag is a PHP open source software and its code is entirely available on github.
You can self-host Wallabag but if you don’t have the necessary technical skills or if you want to financially support the project, the Wallabag team has a paid hosting offer with wallabag.it.
For a very fait price of 9€/year, you won’t have to worry about hosting.
Installation
If you still want to install the self-hosted version, there is an official docker image, available here.
Here is an sample docker-compose file (it is recommended to change the passwords):
version: '3'
services:
wallabag:
image: wallabag/wallabag
environment:
- MYSQL_ROOT_PASSWORD=wallaroot
- SYMFONY__ENV__DATABASE_DRIVER=pdo_mysql
- SYMFONY__ENV__DATABASE_HOST=db
- SYMFONY__ENV__DATABASE_PORT=3306
- SYMFONY__ENV__DATABASE_NAME=wallabag
- SYMFONY__ENV__DATABASE_USER=wallabag
- SYMFONY__ENV__DATABASE_PASSWORD=wallapass
- SYMFONY__ENV__DATABASE_CHARSET=utf8mb4
- SYMFONY__ENV__MAILER_HOST=127.0.0.1
- SYMFONY__ENV__MAILER_USER=~
- SYMFONY__ENV__MAILER_PASSWORD=~
- SYMFONY__ENV__FROM_EMAIL=wallabag@example.com
- SYMFONY__ENV__DOMAIN_NAME=http://wallabag.docker.home
ports:
- "80"
volumes:
- /opt/wallabag/images:/var/www/wallabag/web/assets/images
db:
image: mariadb
environment:
- MYSQL_ROOT_PASSWORD=wallaroot
volumes:
- /opt/wallabag/data:/var/lib/mysql
redis:
image: redis:alpine
Run the containers:
docker-compose up -d
Once the containers are launched, you will be able to find your wallabag instance at your server IP address and on port 80. The default IDs are wallabag / wallabag.
General interface

Add an article

Adding an article is very easy, you can click on the + button in the web interface. It is also possible to add articles from the Android and iOS applications (see below) or to mass import them in the settings.
For each article, Wallabag will be able to estimate a reading time and display it on the homepage.
Wallabag is also able to extract content under “paywall” from a selection of websites if you have a subscription, more information here. The compatible websites include LWN.net and The Economist.
Mass import
Wallabag has a very useful link import feature: wallabag is able to add a series of links from competing services such as Pocket or Readability, or to import a list of bookmarks from Firefox or Chrome.
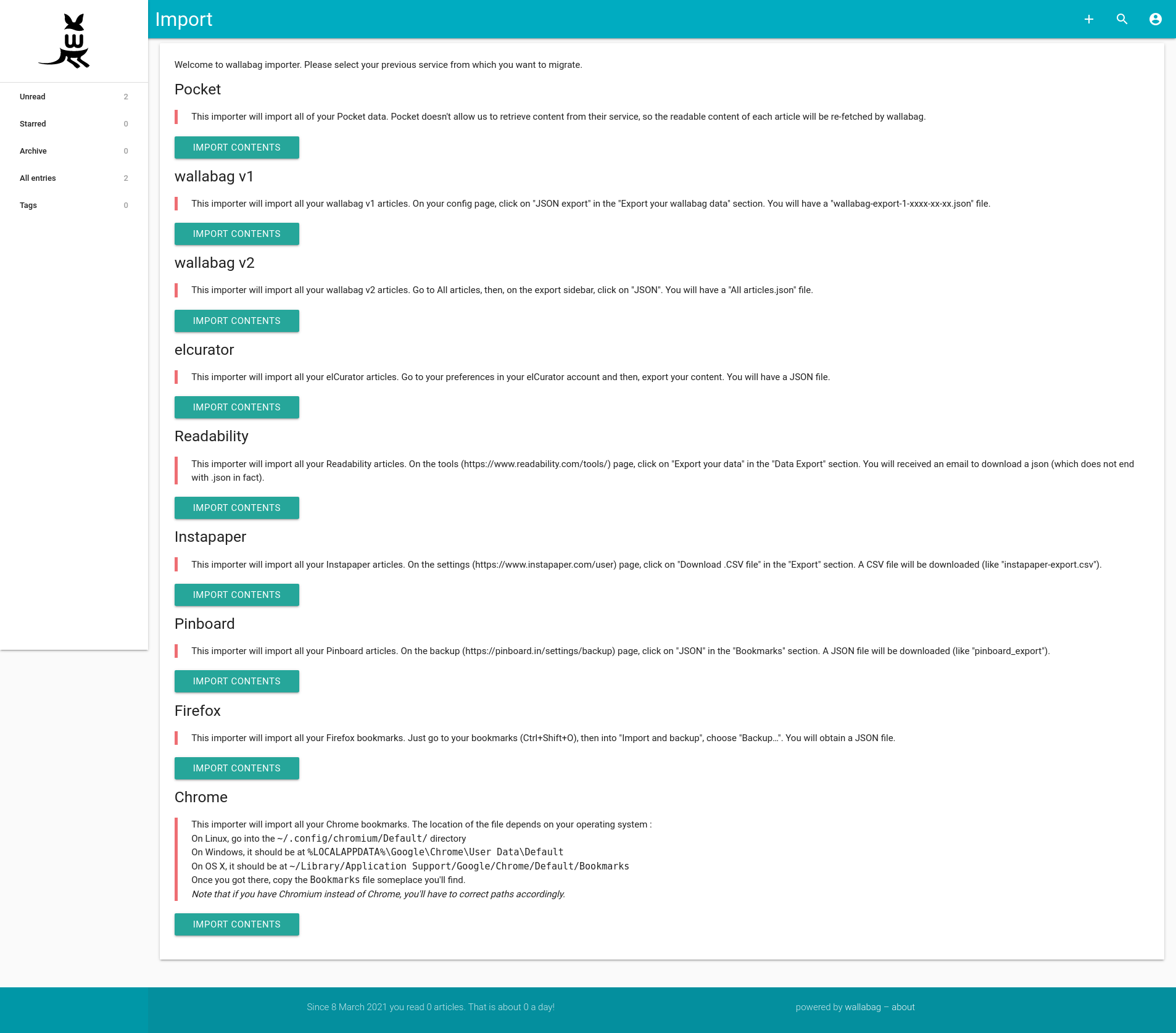
List view
The list view allows you to select several articles. You can delete them, mark them as read or bookmark them. The number of displayed articles per page is configurable (12 by default but I advise you to increase this number).
Reader
The integrated reader allows you to read the archived content.
It is possible to re-download the article, access the original link or add annotations by selecting the text.
Export
The reader allows you to export the content of articles in different formats: EPUB, MOBI, PDF, CSV, JSON, TXT and XML.
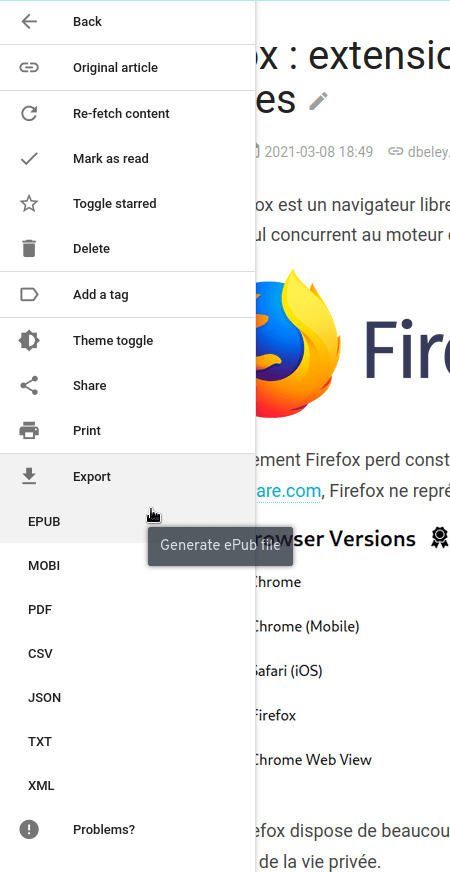
Mass export

Like the import feature, Wallabag allows the mass export of articles to the various supported formats. This feature is found on the home page under the name Export.
RSS Feed
Wallabag can export an RSS feed of all its articles in order to read them via an RSS feed reader. This feature can be configured in the settings from the Feed section.
Comparison between the original article and its rendering in Wallabag
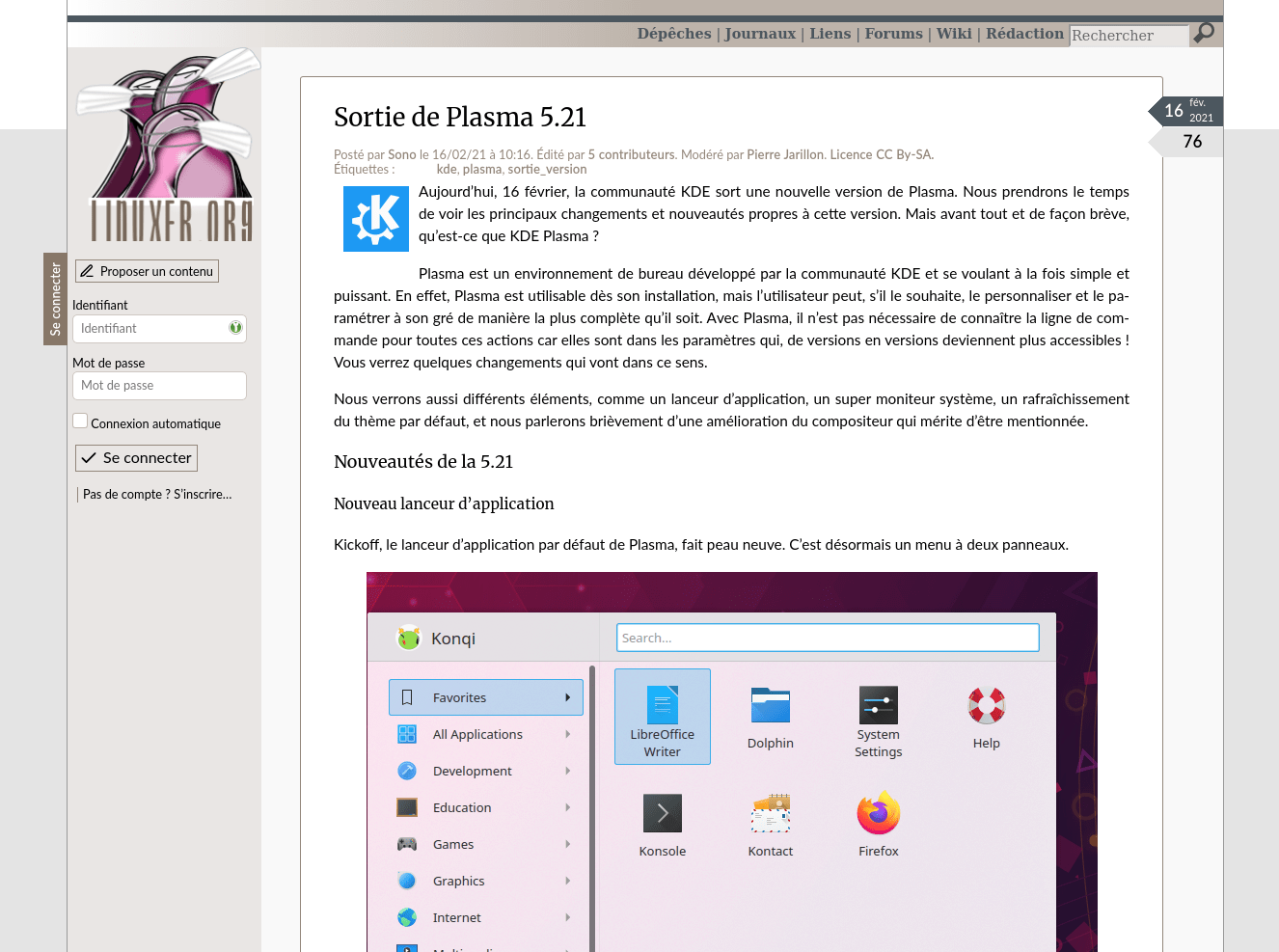
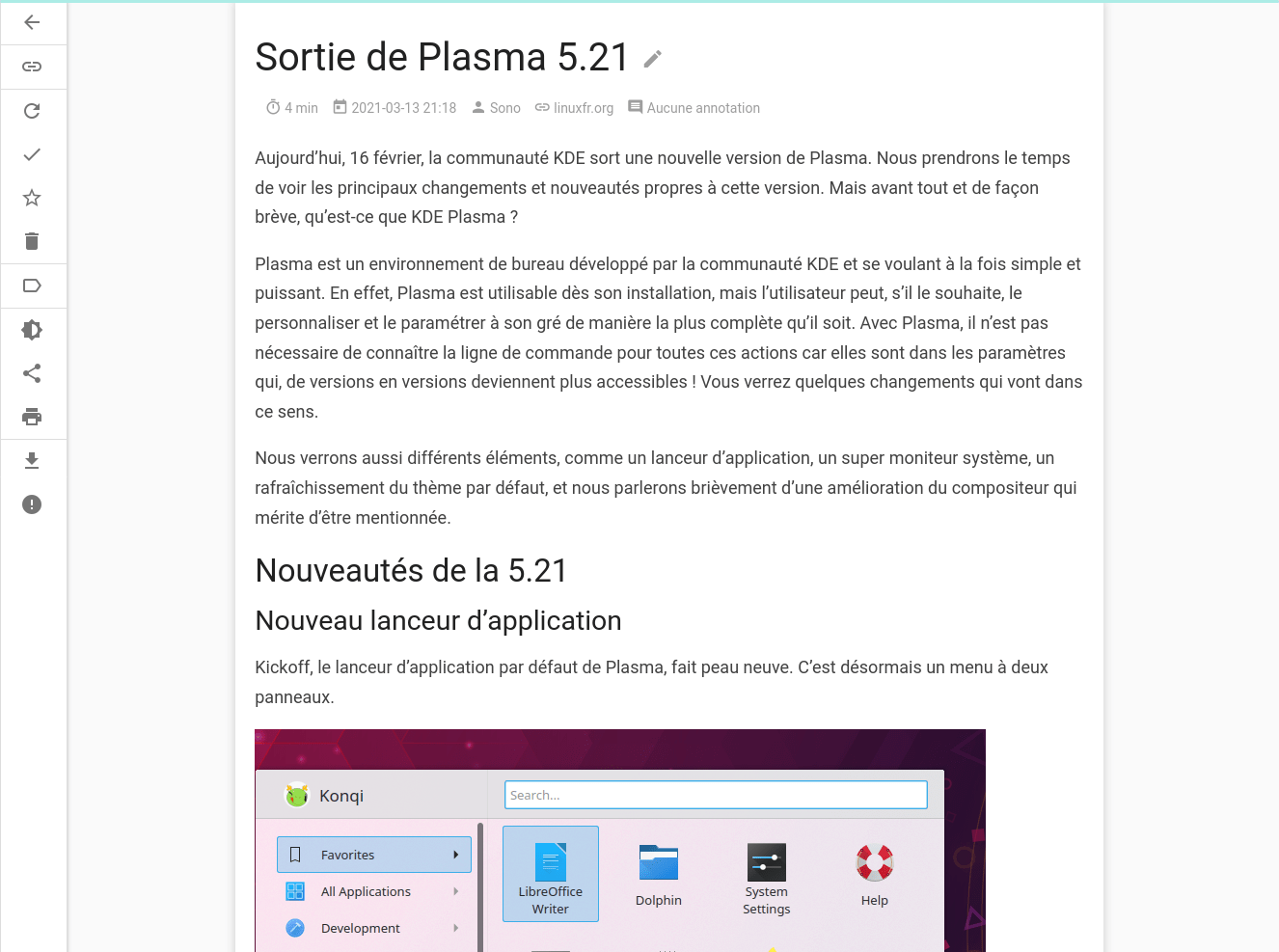
An article from linuxfr.org:
An article from lemonde.fr:
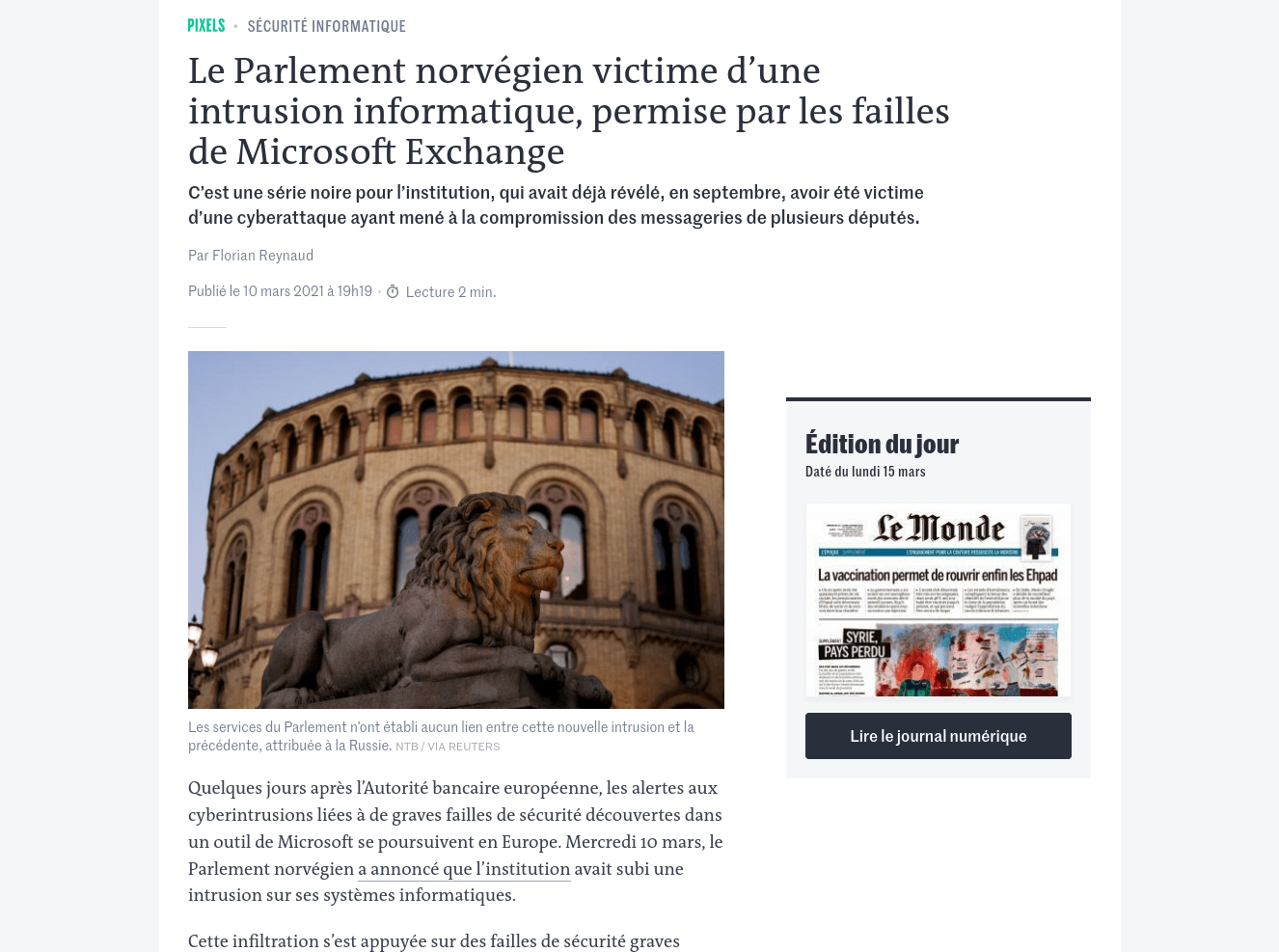
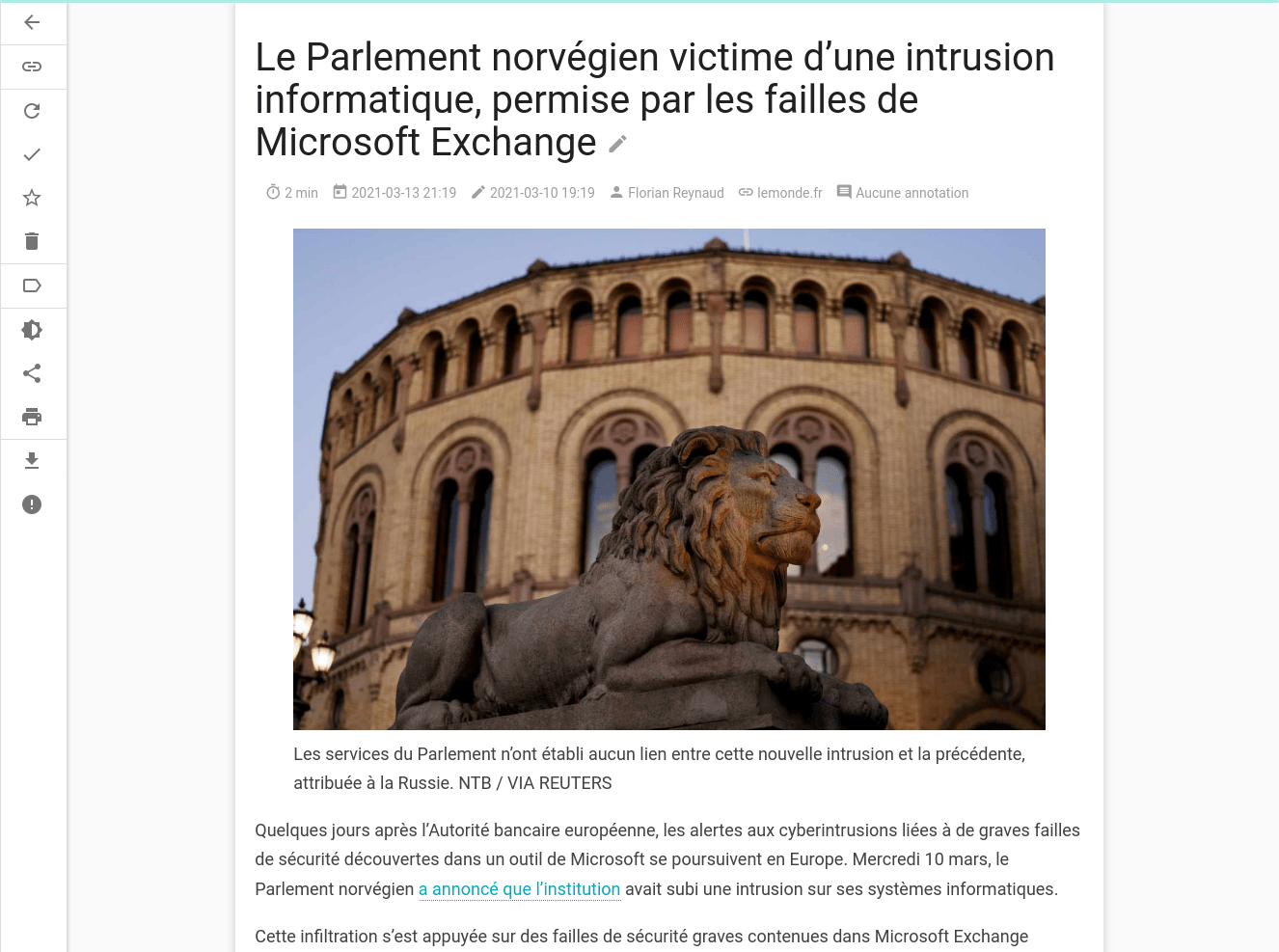
As we can see, the reading experience is very similar to the original content and no important information is lost.
Dark theme
It is also possible to activate a dark theme in the reader options.

Applications
In addition to the web application, Wallabag has other software making it easy to add links and/or access wallabag content on other devices:
- Firefox extension (wallabagger)
- Chrome extension (wallabagger)
- Android app (wallabag)
- iOS app (wallabag 2 official)
- Windows app (wallabag)
- E-reader apps:
Conifer
Presentation
Conifer is a webapp to archive web pages.
It can be seen as an equivalent to archive.org and uses the same file format (WARC).

Source: conifer.rhizome.org
This service is developed by the non-profit organization Rhizome based on Webrecorder software.
The two organizations are closely related but differ in their approach: Rhizome focuses on the business and product side, Webrecorder on the free software and tools side.

Source: conifer.rhizome.org
Conifer offers a free-tier with 5 GB of storage space. In order to have more storage you will have to pay $20/month or $200/year, which will give access to 40 GB of storage.
It is possible to further extend the storage for a cost of $5/month (or $50/year) per 20 GB.

Source: conifer.rhizome.org
Unlike other services on the internet, free account data is not used or resold. Conifer’s only funding comes from subscriptions and donations.
Usage
Conifer works in a very simple way: it integrates a browser that will capture everything. Just browse the web and Conifer will store and archive the content.
Conifer allows for the archiving of non-public content (behind authentication). All you have to do is log in to a site and browse it.
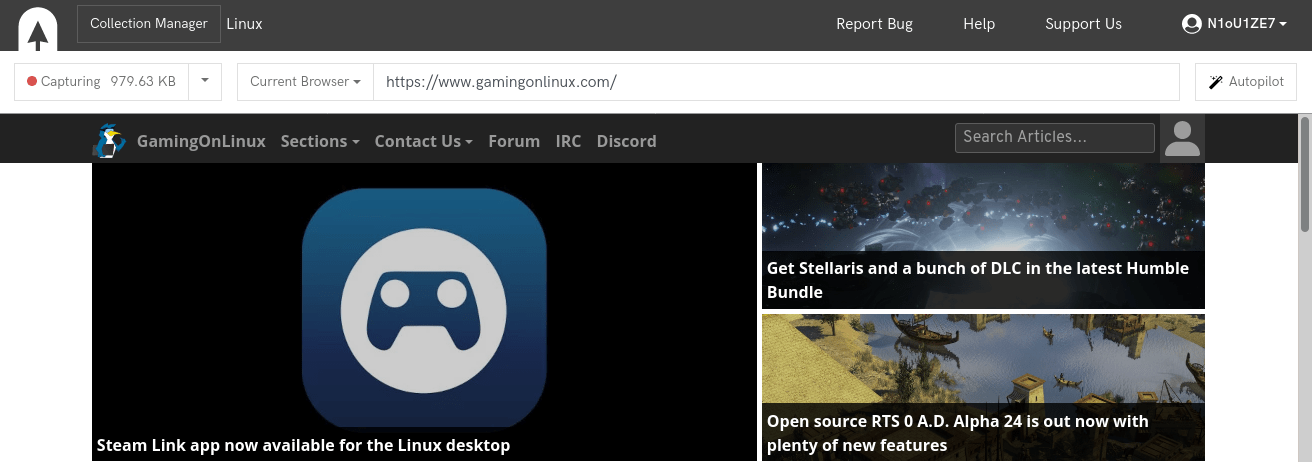
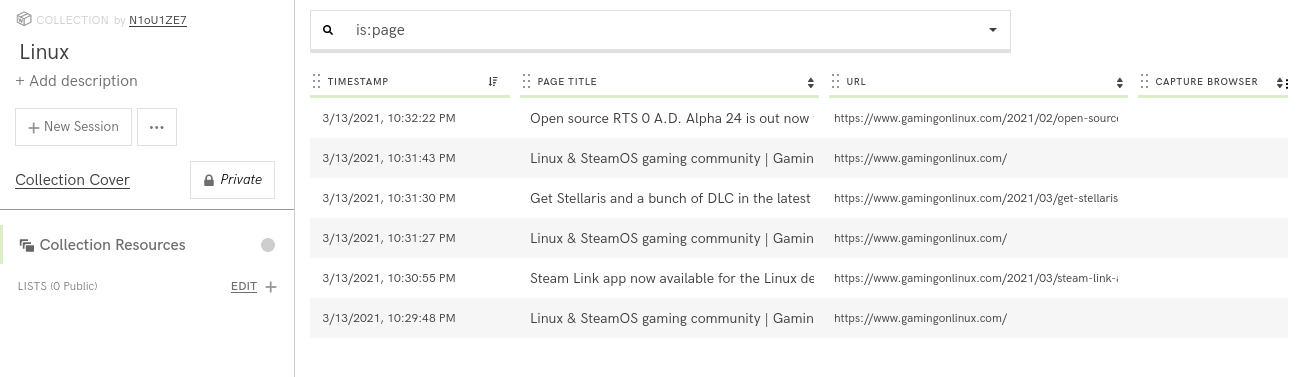
The captures are organized into collections. A collection can contain as many links as possible and can be exported to a WARC file.
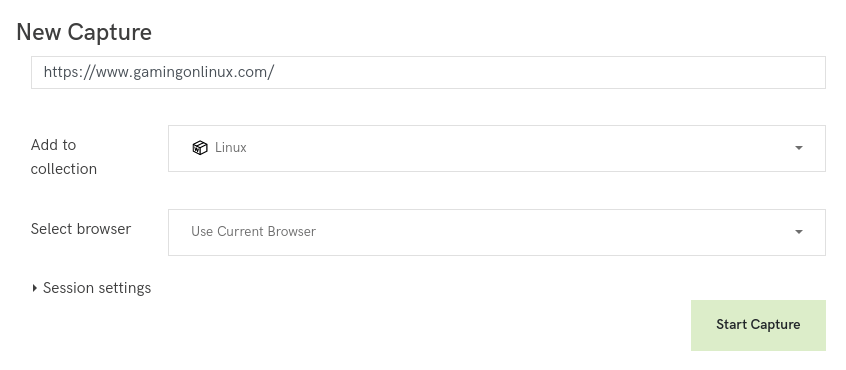
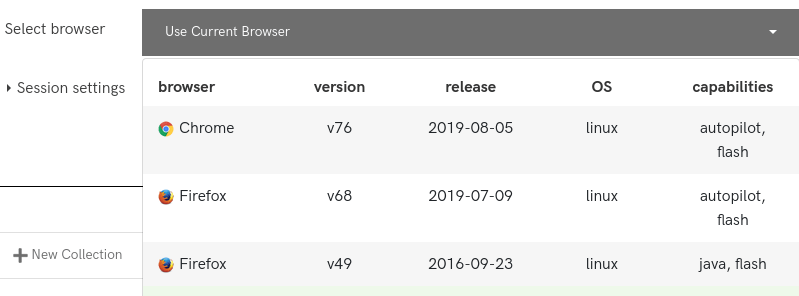
It is possible to configure the browser used for content extraction. The choices are Chrome 76, Firefox 68, Firefox 49 or the browser you use to access Conifer.
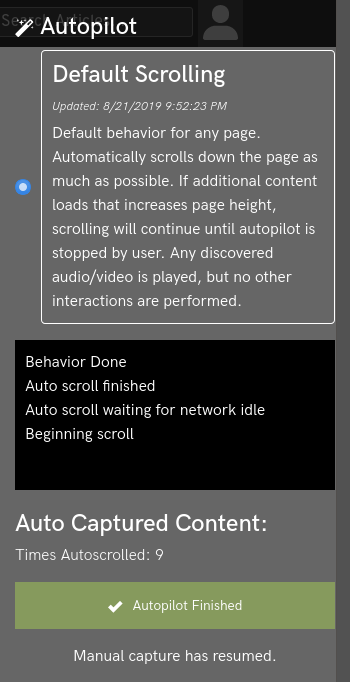
There is also an autopilot feature that automatically scrolls the page and captures audio and video content.
Webrecorder tools
Finally, let’s mention the other tools of the Webrecorder project:
First of all the Chrome/Chromium extension archiveweb.page allows you to create WARC files directly from your own browser. The extension will act in the background and archive all content downloaded by the browser.
This extension works very well and can be a great alternative to Conifer if you don’t want to create an account, its only shortcoming is that it is only compatible with Chromium-based browsers (Chrome, Chromium, etc.).
Another Webrecorder project is the replayweb.page website which allows you to replay WARC files directly from your browser no matter where they come from (Conifer, archiveweb.page, archive.org, etc.).
Archivebox
Presentation
Source: archivebox.io
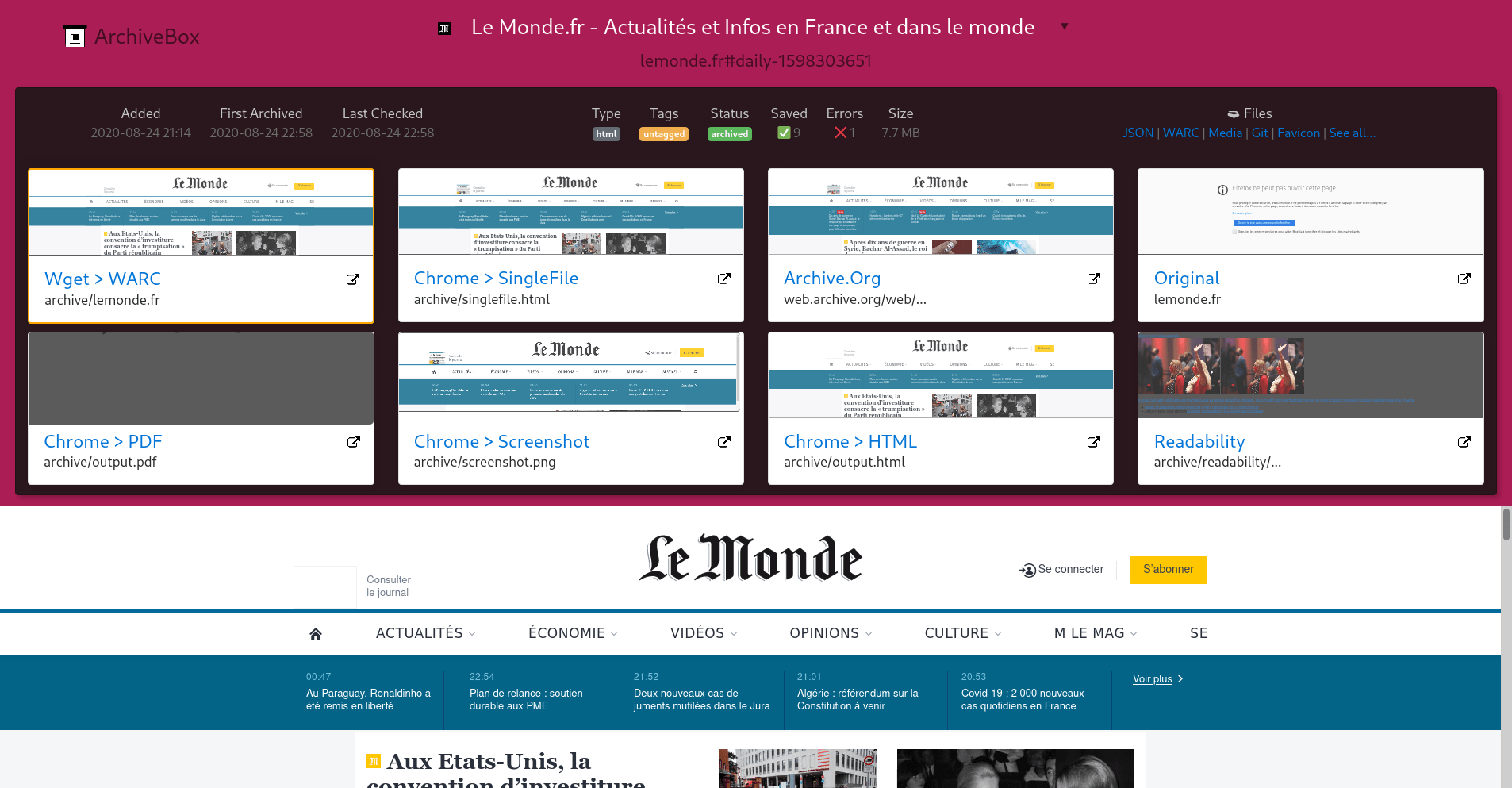
Archivebox is a self-hosting software to archive web pages thanks to a large collection of archiving tools.
Archiving a URL with archivebox can be done with the following methods:
- Download with wget
- Single html file with SingleFile
- Download as PDF
- Screenshot
- Html with Chrome Headless
- Text extraction with readability
- Upload to archive.org
- Media download with youtube-dl
Archivebox is a library built in Python with the Django framework. Its complete source code is available on Github.
This software is more complex than the two previous ones, but it is the most customizable and the one with the most features.
Installation
The recommended installation method uses docker-compose.
First of all, you have to prepare the folder that will contain the archive:
mkdir archivebox
cd archivebox
docker pull nikisweeting/archivebox:latest
docker-compose run archivebox init
docker-compose run archivebox manage createsuperuser
Here is an example docker-compose file (change DATA_FOLDER to the location of the previously created archive):
---
version: "3.7"
services:
archivebox:
image: nikisweeting/archivebox:latest
command: server 0.0.0.0:8080
stdin_open: true
tty: true
container_name: archivebox
environment:
- USE_COLOR=True
- SHOW_PROGRESS=False
- TIMEOUT=120
- MEDIA_TIMEOUT=300
volumes:
- /DATA_FOLDER:/data
ports:
- 8080:8080
restart: unless-stopped
Run the container:
docker-compose up -d
The Archivebox web UI will be available on port 8080 of your server.
Usage
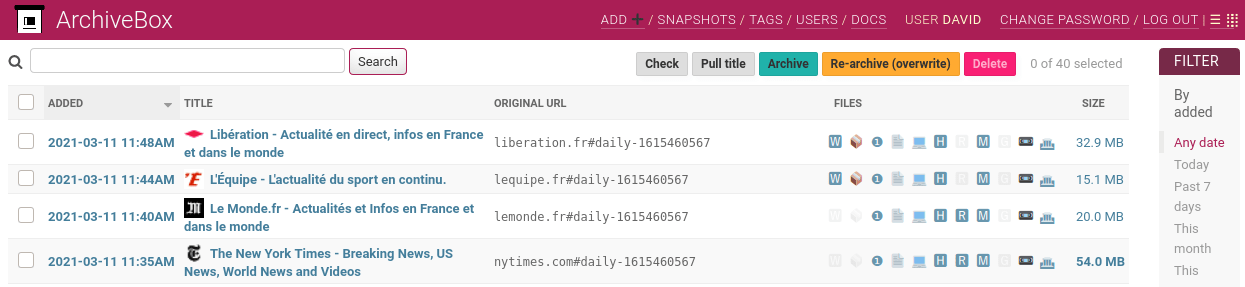
Archivebox can be used from its web UI that will list all archives or with a command line tool.
Adding a URL to the archive via the command line:
docker-compose run archivebox add 'https://example.com'
# if you also want to archive the content of the links on the page
docker-compose run archivebox --depth=1 add 'https://example.com'
You can also add links from the web interface.
An important limitation of Archivebox is its inability to archive twice the same URL. Fortunately this shortcoming can be overcome.
For example if you want to archive a media homepage on a regular basis to create a timeline of the different headlines that have made the news, you can get around the limitation by adding invalid text to the URL.
# Example: first extraction of the example.com site
docker-compose run archivebox add 'https://example.com#1'
# Later, second extraction of example.com
docker-compose run archivebox add 'https://example.com#2'
I personally add the current timestamp to the URL, for example https://lemonde.fr#daily-1615460567.
For more information, you can check this bug report: https://github.com/ArchiveBox/ArchiveBox/issues/179
The add command of archivebox also allows to extract links from a file. For example, to archive all the URLs contained in a text file:
docker-compose run archivebox add < 'URLs.txt'
Another feature is the ability to schedule extractions with the schedule command. The --every option accepts hour/day/month/year values or a value in cron format like "0 0 * * *".
This schedule function will only add links that have never been archived. This can be useful to monitor an RSS feed or a list of bookmarks. Note that the depth=1 option that allows the extraction of the URLs contained in the file and not only the file itself.
docker-compose run archivebox schedule --depth=1 --every=day 'URLs.txt'
It is possible to display the scheduled extractions with the --show option and to delete them all with --clear.
docker-compose run archivebox schedule --show
docker-compose run archivebox schedule --clear
Even though Archivebox is a program that I really like, not everything is perfect.
Some simple operations like listing archives via the web interface are very long and can cause the whole program to crash. Moreover, the software suffers from a certain lack of finish (the file/URL distinction in the add functions and their management is rather opaque) and some features such as the use of archivebox in command line or the Python API are scarcely documented: the official documentation has many duplicated pages and incomplete information.
It is still a program that has a lot of potential, but it has its shortcomings.
Conclusion
These three software are quite complementary, they can all three archive web content but with different approaches.
Wallabag will be perfect for users interested in saving content for re-reading purposes, while Conifer will delight those who prefer to archive content in its most original form (a la Wayback Machine), at the cost of a more difficult re-reading experience.
Archivebox on the other side tries to preserve as much as possible by archiving the pages with a wide range of tools. This is done at the cost of a greater complexity.
Those tools are not intended for archiving videos or audio files. If this is your use case (for example to archive content from a youtube channel), you can look at youtube-dl. As its name does not indicate, youtube-dl is compatible with a large number of services such as youtube, dailymotion, twitch or vimeo.
Have a comment? React on Mastodon!
>> Home