Introduction
Le mercredi 10 mars 2021, un datacenter d’OVH situé à Strasbourg a connu un incendie dévastateur détruisant une partie de ses serveurs et rendant inaccessibles plus de 400 000 noms de domaines distincts.
Cet évènement nous rappelle de manière dramatique que le web est fragile et que tout contenu qui y est présent peut disparaître à tout moment.
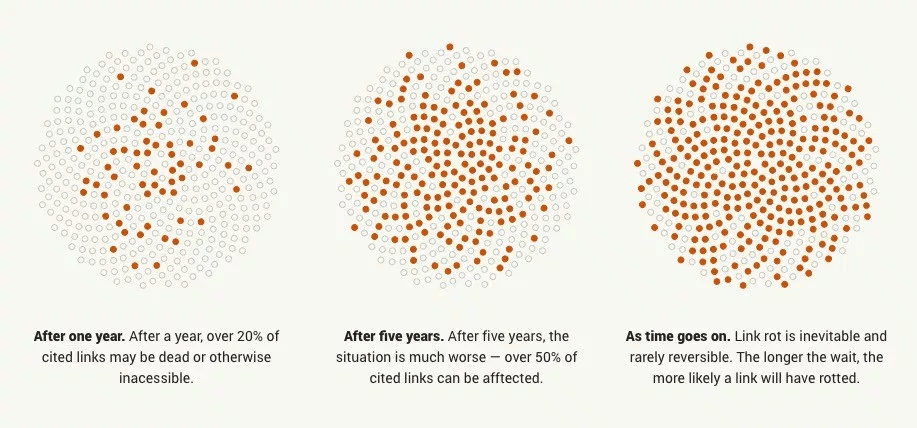
Ce phénomène où un lien vers un document ou une page web cesse de fonctionner est connu sous le nom de Link Rot (que l’on pourrait traduire par pourrissement des liens ou encore érosion des liens).
Source : perma.cc
Le Link Rot peut se produire après un accident matériel comme avec l’incendie du datacenter d’OVH, mais peut aussi être la conséquence d’autres phénomènes : faillite d’une entreprise, modération de contenu, ou même piratage.
Une étude de 2013 a ainsi analysé près de 15 000 liens et a trouvé que la durée de vie médiane des liens était de 9,3 ans. Un autre exemple assez extrême d’érosion des liens, Ernie Smith n’a trouvé aucun lien fonctionnel dans un livre à propos d’internet datant de 1994.
Pour n’importe quel contenu du web, la question n’est pas de savoir s’il va devenir inaccessible, mais quand est-ce qu’il le deviendra.
Heureusement des initiatives comme archive.org (plus particulièrement son projet Wayback Machine) existent et archivent un nombre très important de pages web (plus de 549 milliards pour Wayback Machine).

Source : archive.org
On peut aussi citer ArchiveTeam qui maintient notamment une “Deathwatch” des sites dont le contenu est menacé de suppression ou encore la BnF (Bibliothèque nationale de France) dont les archives représentent plus d'1 pétaoctet de données.
En plus de ces initiatives il peut être intéressant de se constituer une archive personnelle afin de prévenir la perte du contenu que nous considérons comme important.
Ce contenu peut aller de l’article de blog à un post sur un réseau social en passant par des documents glanées au hasard de nos recherches sur internet.
Dans cet article, je passerai en revue trois outils permettant d’archiver du contenu de pages web : Wallabag, Conifer et Archivebox.
Les versions utilisées au moment de la création de cet articles sont les suivantes :
- Wallabag : 2.4.1
- Archivebox : 0.5.6
Wallabag
Présentation
Wallabag est un service de lecture différée permettant de sauvegarder et classifier des pages web pour les consulter plus tard.
Lors de l’ajout d’une page web à Wallabag, celui-ci se chargera d’extraire le texte et les images de cette page.
Ainsi, si cette page devenait inaccessible, il sera toujours possible de la lire via Wallabag.

Source : wallabag.org
D’un point de vue technique, Wallabag est une application web développée en PHP dont le code source est libre et entièrement disponible sur github.
Il est donc possible d’auto-héberger Wallabag mais si vous ne possédez pas les compétences techniques nécessaires ou souhaitez soutenir financièrement le projet, l’équipe de Wallabag propose une offre d’hébergement payante avec wallabag.it.
Pour un coût très correct de 9€/an, vous n’aurez pas à vous souciez de l’hébergement du logiciel.
Installation
Si vous souhaitez tout de même vous lancer dans l’installation de la version auto-hébergée, il existe une image docker officielle, disponible ici.
Voici un fichier docker-compose d’exemple (il est vivement conseillé de changer les mots de passe) :
version: '3'
services:
wallabag:
image: wallabag/wallabag
environment:
- MYSQL_ROOT_PASSWORD=wallaroot
- SYMFONY__ENV__DATABASE_DRIVER=pdo_mysql
- SYMFONY__ENV__DATABASE_HOST=db
- SYMFONY__ENV__DATABASE_PORT=3306
- SYMFONY__ENV__DATABASE_NAME=wallabag
- SYMFONY__ENV__DATABASE_USER=wallabag
- SYMFONY__ENV__DATABASE_PASSWORD=wallapass
- SYMFONY__ENV__DATABASE_CHARSET=utf8mb4
- SYMFONY__ENV__MAILER_HOST=127.0.0.1
- SYMFONY__ENV__MAILER_USER=~
- SYMFONY__ENV__MAILER_PASSWORD=~
- SYMFONY__ENV__FROM_EMAIL=wallabag@example.com
- SYMFONY__ENV__DOMAIN_NAME=http://wallabag.docker.home
ports:
- "80"
volumes:
- /opt/wallabag/images:/var/www/wallabag/web/assets/images
db:
image: mariadb
environment:
- MYSQL_ROOT_PASSWORD=wallaroot
volumes:
- /opt/wallabag/data:/var/lib/mysql
redis:
image: redis:alpine
Lancez les conteneurs :
docker-compose up -d
Une fois les conteneurs lancés, vous pourrez retrouver votre instance wallabag à l’adresse IP de votre serveur et sur le port 80. Les identifiants par défaut sont wallabag / wallabag.
Interface générale

Ajout d’un article
 L’ajout d’un article se fait très simplement en cliquant sur le bouton + dans l’interface web. Il est aussi possible d’ajouter des articles depuis les applications Android et iOS (voir plus bas) ou encore d’en importer massivement dans les paramètres.
L’ajout d’un article se fait très simplement en cliquant sur le bouton + dans l’interface web. Il est aussi possible d’ajouter des articles depuis les applications Android et iOS (voir plus bas) ou encore d’en importer massivement dans les paramètres.
En fonction de la longueur du texte, Wallabag sera capable d’estimer un temps de lecture par article et l’affichera sur la page d’accueil.
À noter que wallabag est capable d’extraire du contenu sous “paywall” d’une sélection de sites web si vous avez un abonnement, plus d’informations ici. Parmi les sites compatibles, on peut citer Arrêt sur Images, Canard PC, Le Figaro, Le Monde, Le Monde Diplomatique, Mediapart ou encore Next INpact.
Import massif
Wallabag dispose d’une fonction très pratique d’import massif de liens : wallabag est capable d’ajouter une série de liens provenant de services concurrents comme Pocket ou Readability, ou encore d’importer une liste de favoris provenant de Firefox ou Chrome.
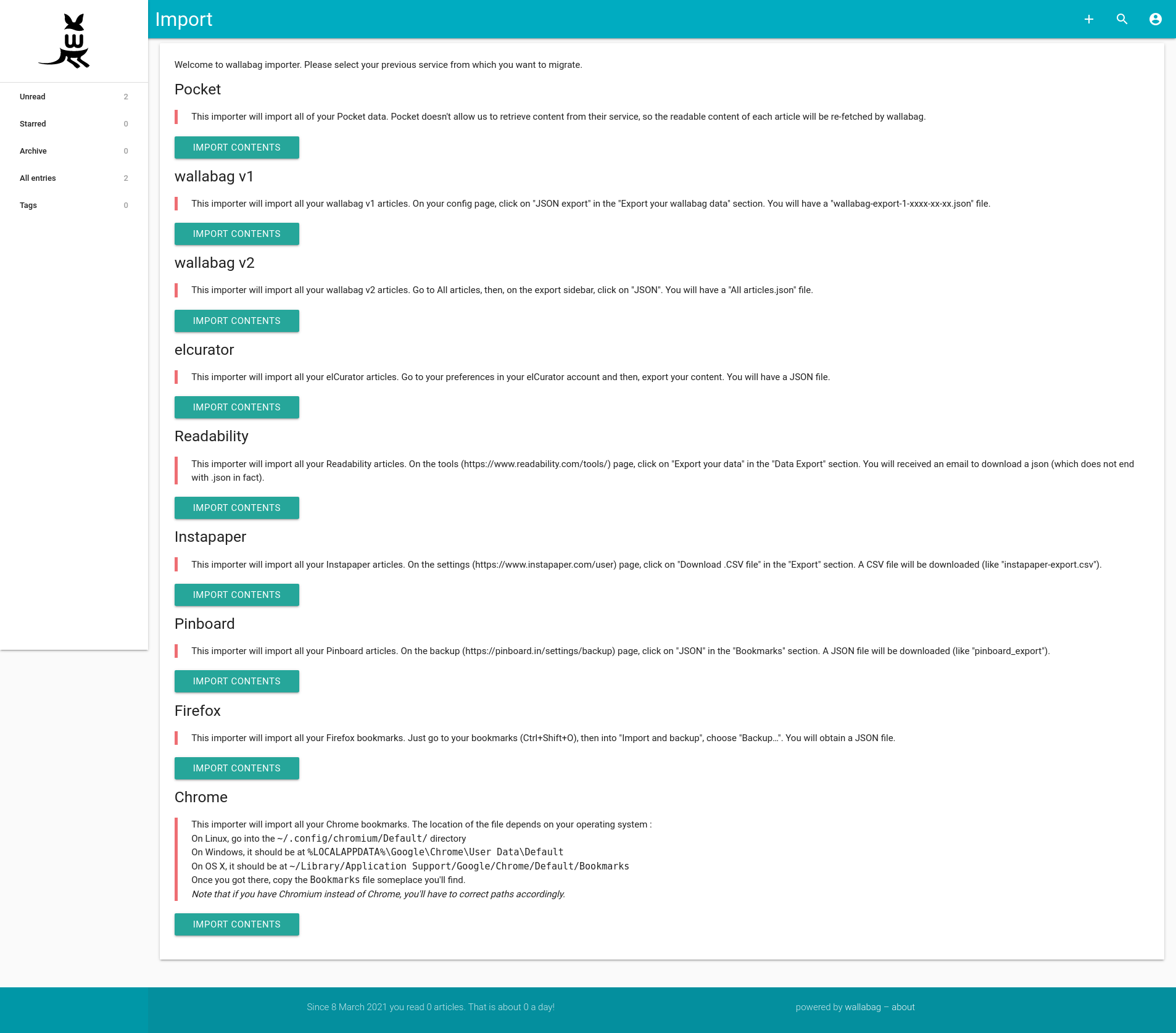
Vue liste
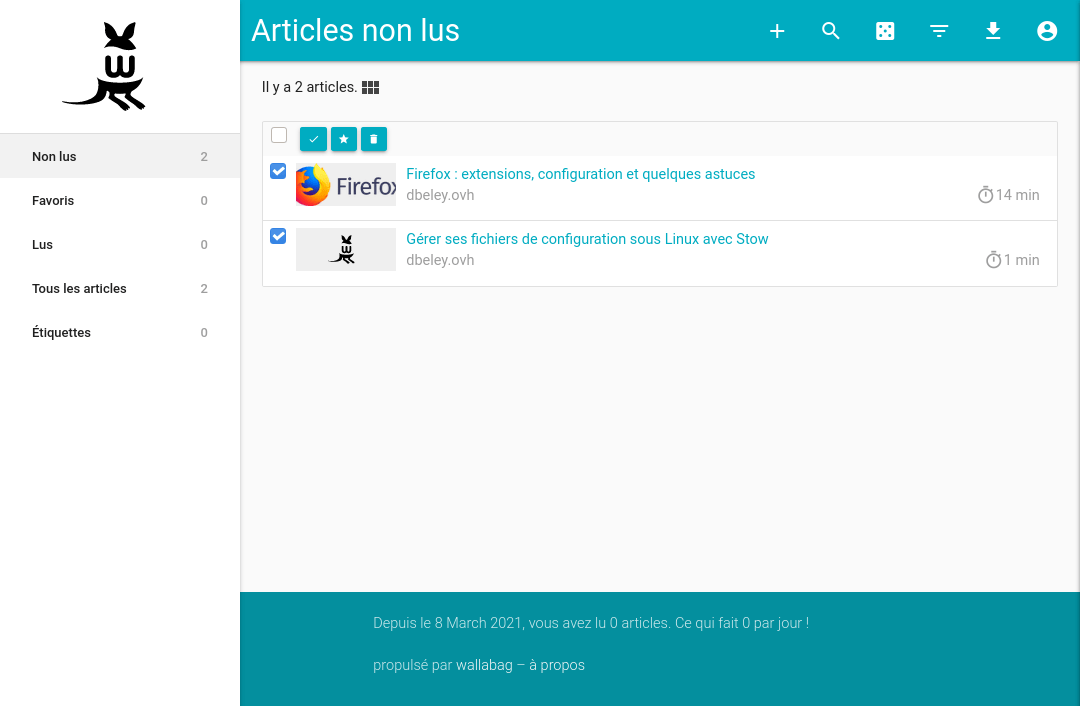
La vue liste permet de sélectionner plusieurs articles. On pourra ainsi supprimer une sélection d’articles, les noter comme lus ou les mettre en favoris. Le nombre d’articles s’affichant par page est configurable (par défaut 12 mais je vous conseille d’augmenter ce nombre).
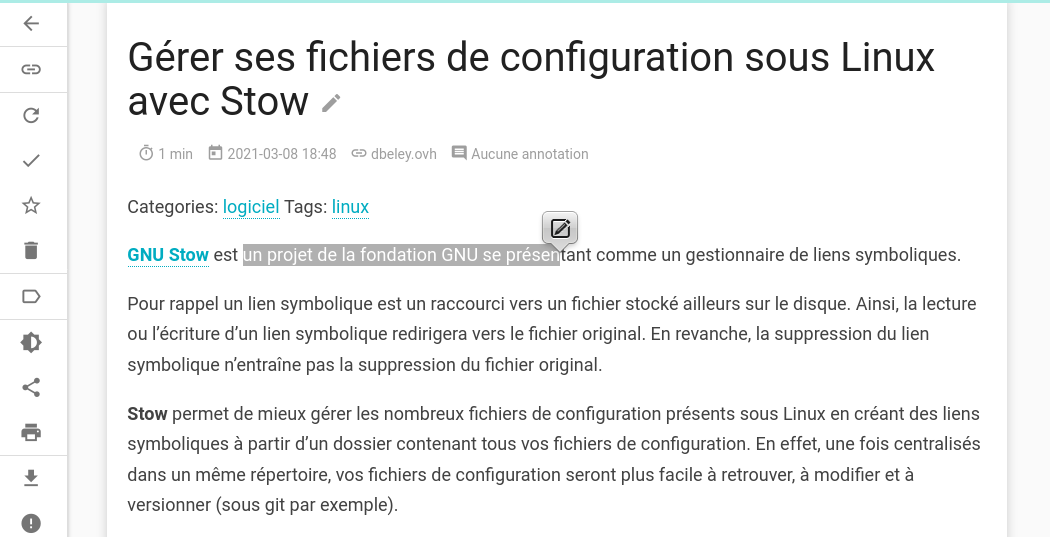
Lecteur
Le lecteur intégré à Wallabag permet de lire le contenu des articles archivés.
Il y est possible de re-télécharger l’article, d’accéder au lien original ou encore d’ajouter des annotations en sélectionnant du texte.
Export d’un article
Le lecteur permet aussi d’exporter le contenu des articles en différents formats : EPUB, MOBI, PDF, CSV, JSON, TXT et XML.
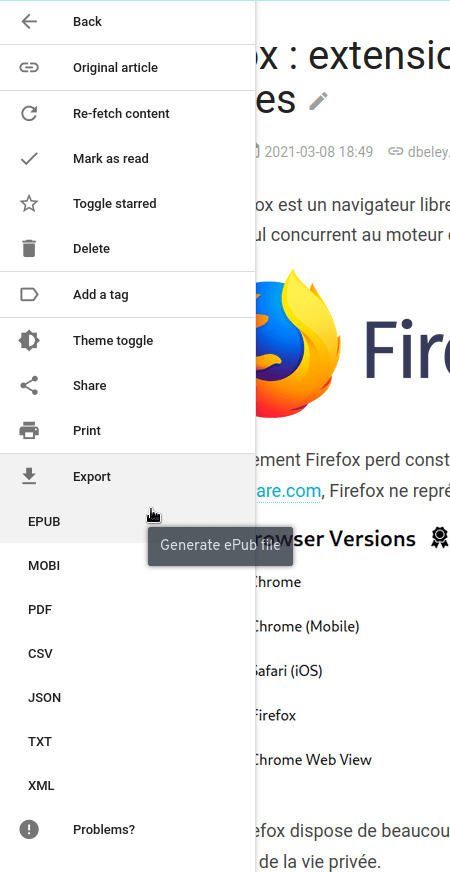
Export massif

Comme pour l’import de liens, Wallabag permet l’export massif d’articles vers les différents formats supportés. Cette fonctionnalité se trouve sur la page d’accueil sous le nom Exporter.
Flux RSS
Wallabag peut exporter un flux RSS de tous ses articles pour pouvoir les lire via un lecteur de flux RSS. Cette fonctionnalité est configurable dans les paramètres à la section Flux.
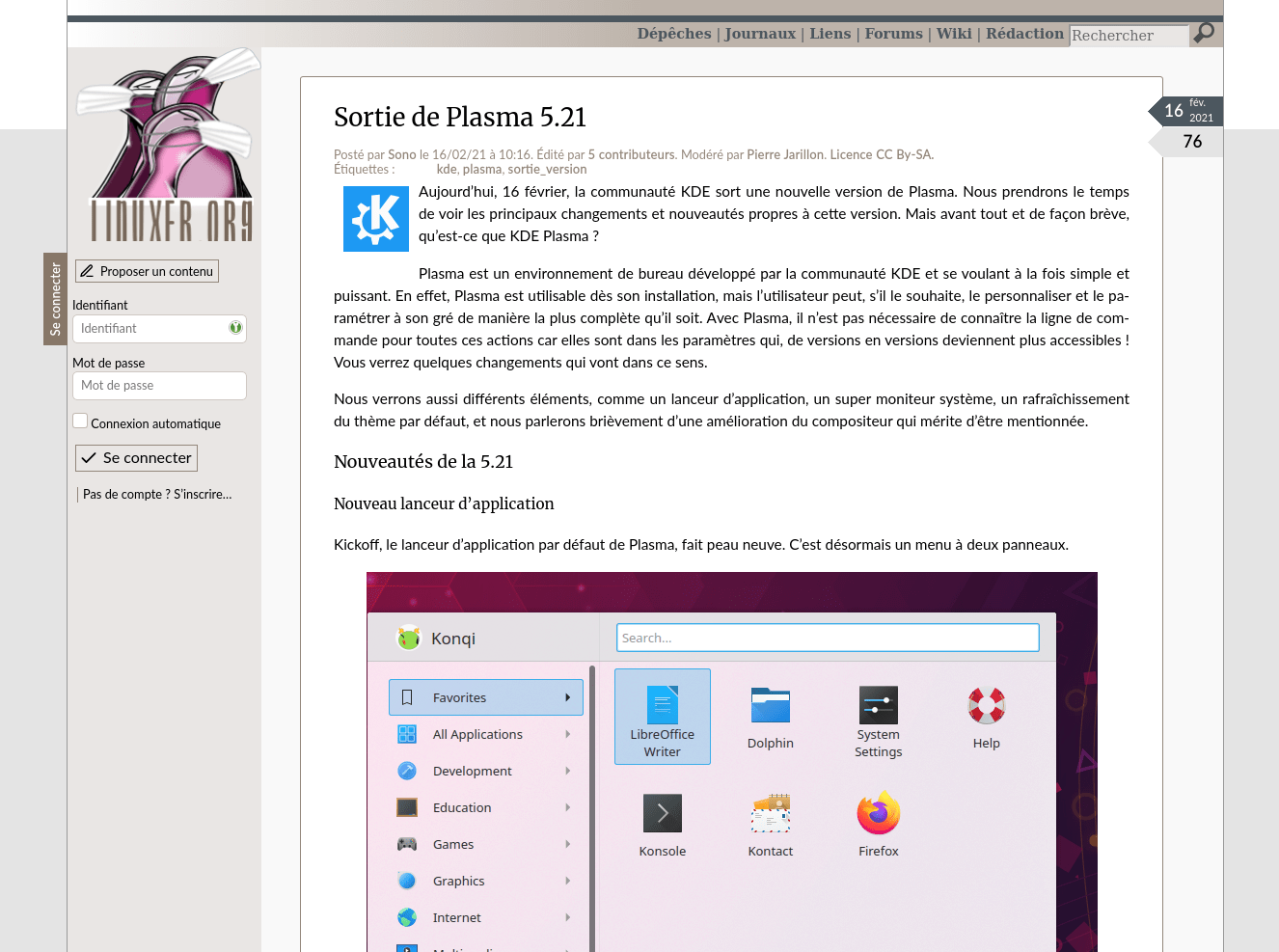
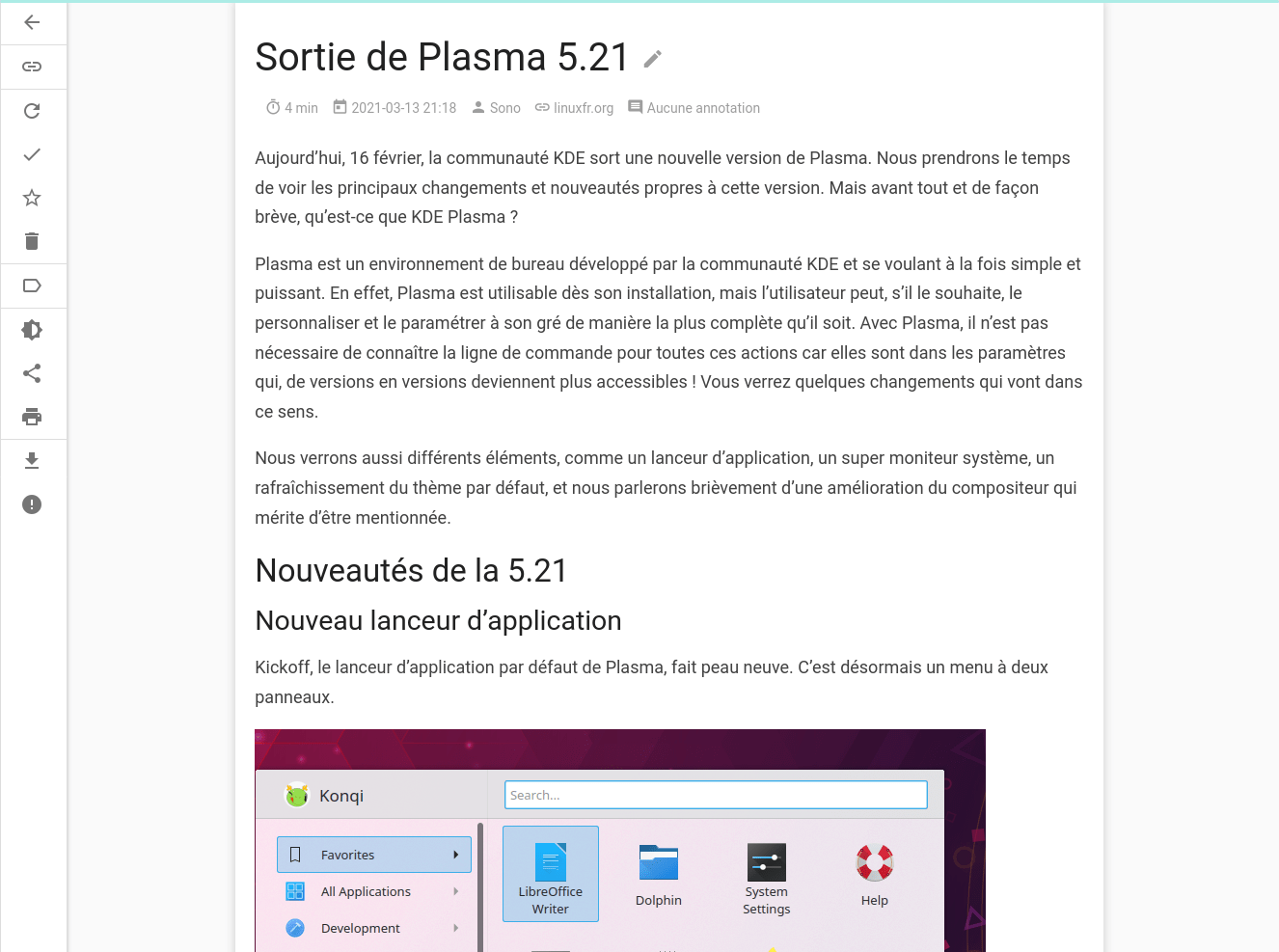
Comparaison entre l’article original et le rendu dans Wallabag
Un article du site linuxfr.org :
Un article du site lemonde.fr :
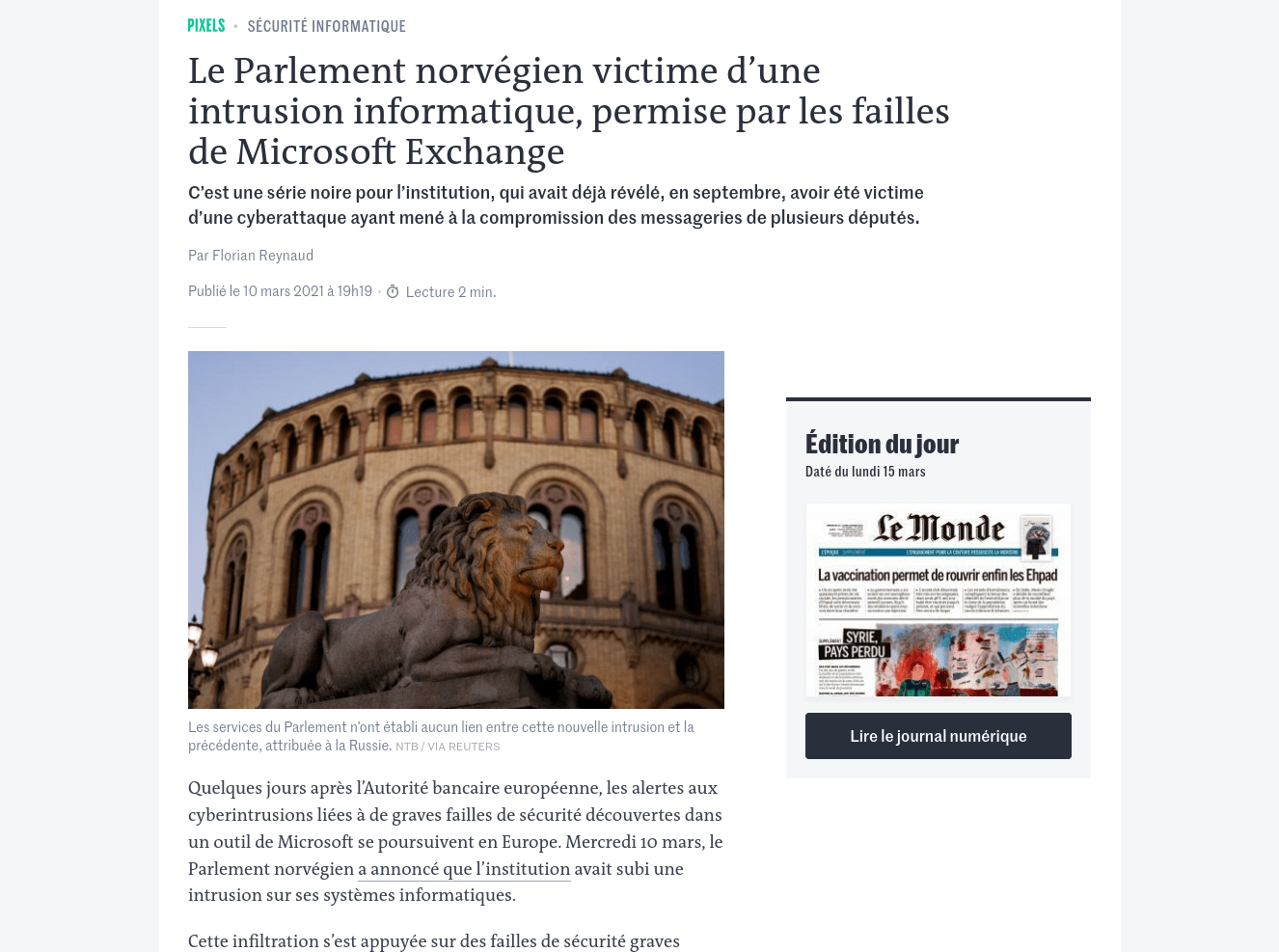
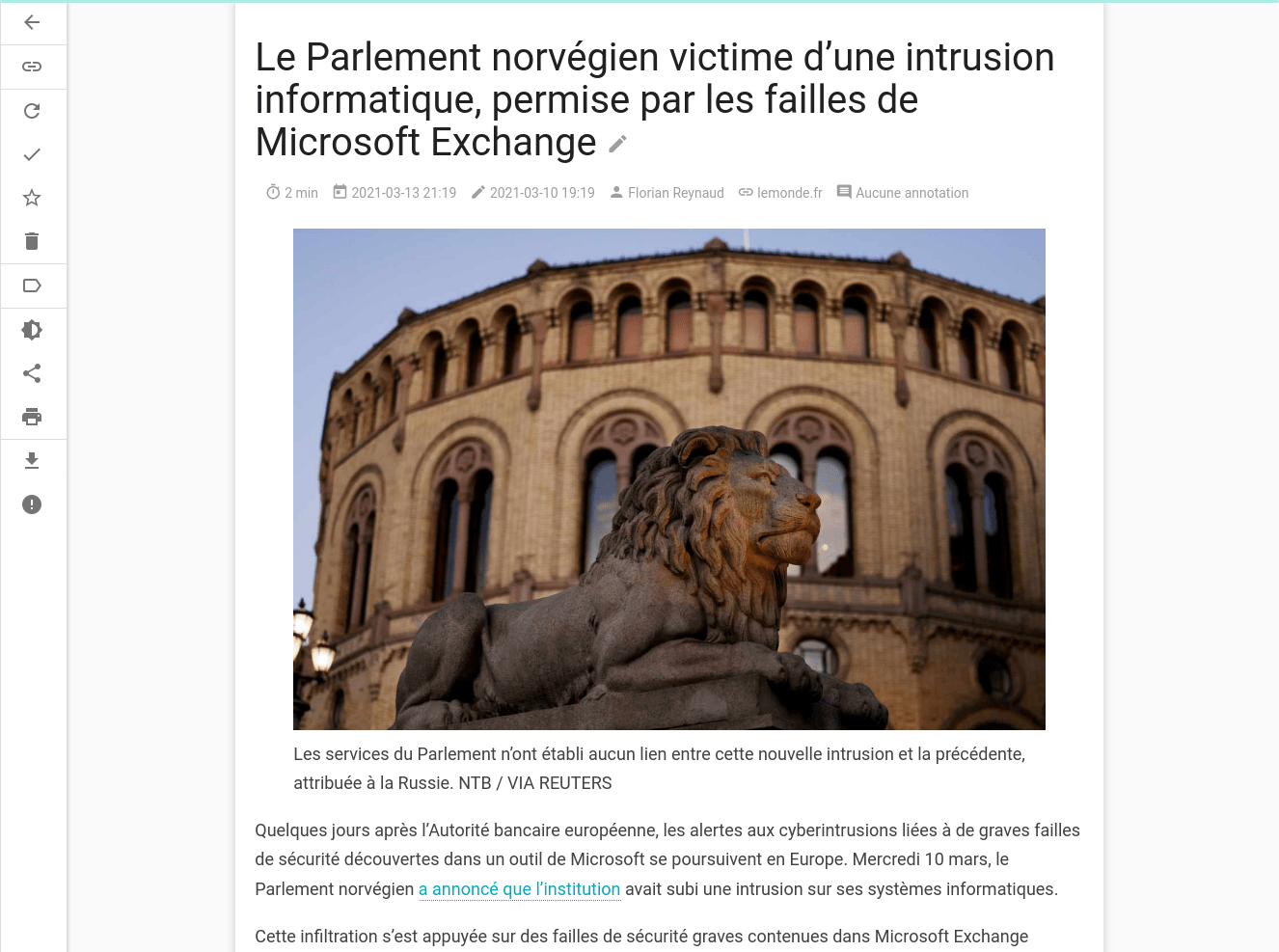
Comme on le voit, l’expérience de lecture est très similaire à celle du contenu original et on ne perd aucune information importante.
Thème sombre
Il est aussi possible d’activer un thème sombre dans les options de lecture.

Applications
En plus de l’application web, Wallabag dispose d’une logithèque bien fournie permettant d’ajouter facilement des liens et/ou d’accéder au contenu de wallabag sur différents appareils :
- Extension Firefox (wallabagger)
- Extension Chrome (wallabagger)
- Application Android (wallabag)
- Application iOS (wallabag 2 official)
- Application Windows (wallabag)
- Applications liseuses :
Conifer
Présentation
Conifer n’est pas un logiciel à proprement parler, mais un service web permettant d’archiver des pages web.
On peut le voir comme un équivalent à archive.org dont il utilise le même format de fichier (WARC).

Source : conifer.rhizome.org
C’est un service développé par l’organisation à but non lucratif Rhizome et basé sur des logiciels de Webrecorder.
Les deux organisations sont très liées mais se distinguent par leur approche : Rhizome se concentre sur l’aspect commercial et produit, Webrecorder sur l’aspect logiciel libre et outils.

Source : conifer.rhizome.org
Conifer propose la création de compte gratuit avec 5 Go d’espace de stockage. Pour avoir plus il faudra payer 20$/mois ou 200$/an, ce qui donnera accès à 40 Go de stockage.
Il est possible d’étendre davantage l’espace de stockage pour un coût de 5$/mois (ou 50$/an) par tranche de 20 Go.
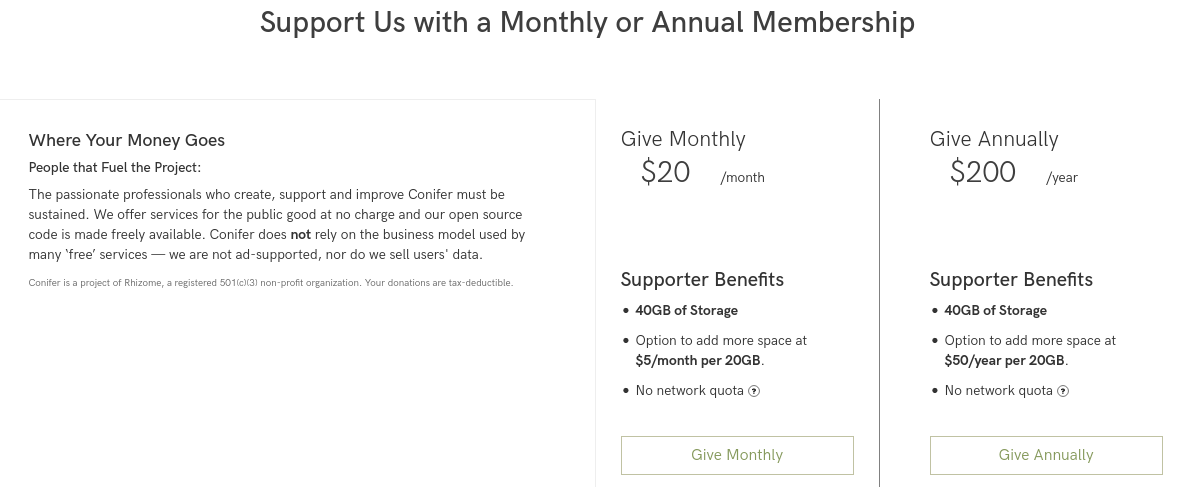
Source : conifer.rhizome.org
Contrairement à d’autres services sur internet, les données des comptes gratuits ne sont ni utilisées ni revendues. Le seul moyen de financement de Conifer provient des abonnements et des dons.
Utilisation
Conifer suit un fonctionnement très simple : il intègre un navigateur dont tout le contenu sera capturé. Il suffira de naviguer sur le web et Conifer se chargera de stocker et archiver le contenu.
De par son fonctionnement, Conifer permet la capture de contenu non-public (derrière une authentification). Il suffit de s’identifier sur un site et d’y naviguer.
Les captures sont organisées en collections. Une collection peut contenir autant de liens que possible et est exportable en un fichier WARC.
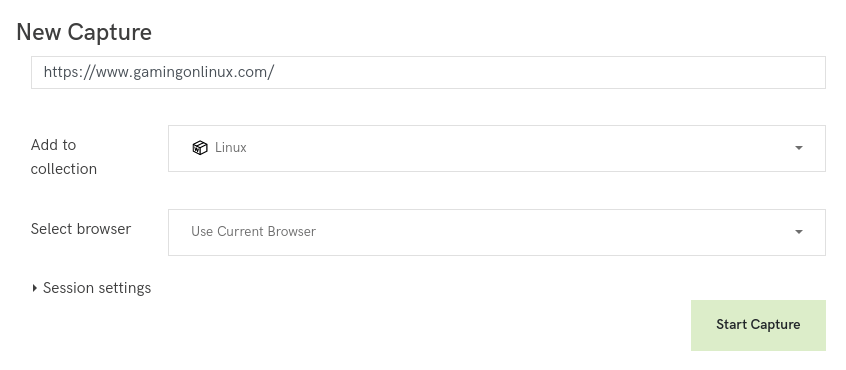
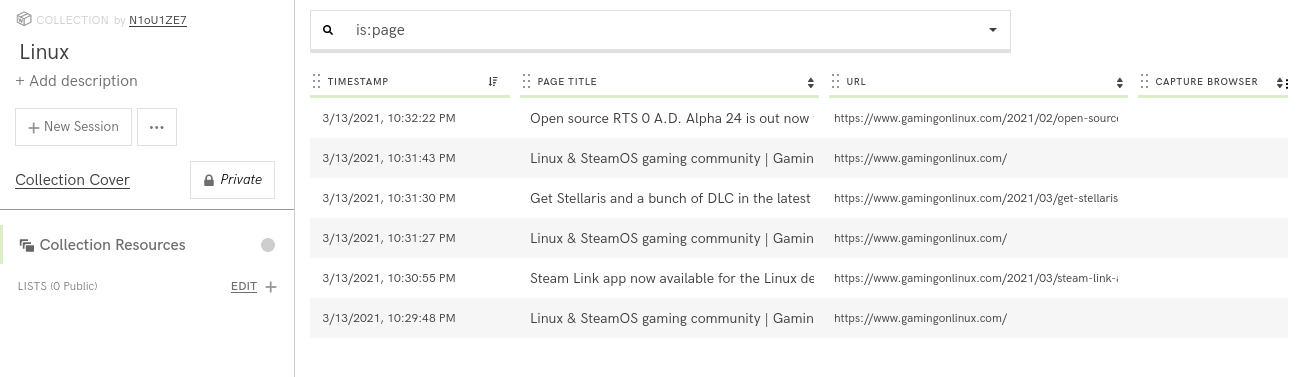
Il est possible de configurer le navigateur utilisé pour l’extraction du contenu. Les choix possibles sont Chrome 76, Firefox 68, Firefox 49 et le navigateur que vous utilisez pour accéder à Conifer.
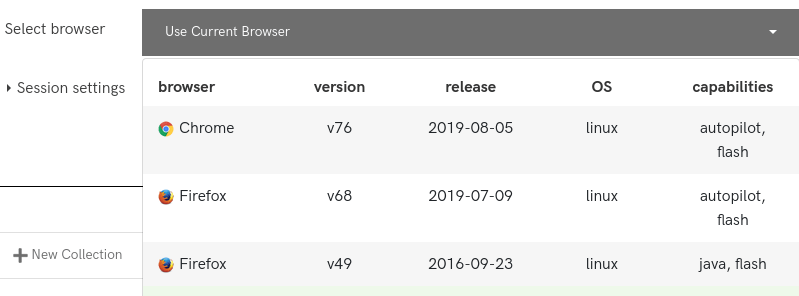
Il existe aussi une fonction d’autopilot qui permet de faire défiler automatiquement la page et de capturer automatiquement le contenu audio et vidéo.
Outils Webrecorder
Pour finir, mentionnons les autres outils du projet Webrecorder :
Tout d’abord l’extension Chrome/Chromium archiveweb.page qui permet de créer des fichiers WARC des pages naviguées. L’extension agira en arrière-plan et archivera tout le contenu téléchargé par le navigateur.
Cette extension fonctionne très bien et peut être une excellente alternative à Conifer si l’on ne souhaite pas créer de compte, son seul défaut est qu’elle n’est compatible qu’avec les navigateurs basés sur Chromium (Chrome, Chromium, etc.).
Un autre projet de Webrecorder est le site replayweb.page qui permet de relire des fichiers WARC directement de son navigateur quelle qu’en soit leur provenance (Conifer, archiveweb.page, archive.org, etc.).
Archivebox
Présentation
Source : archivebox.io
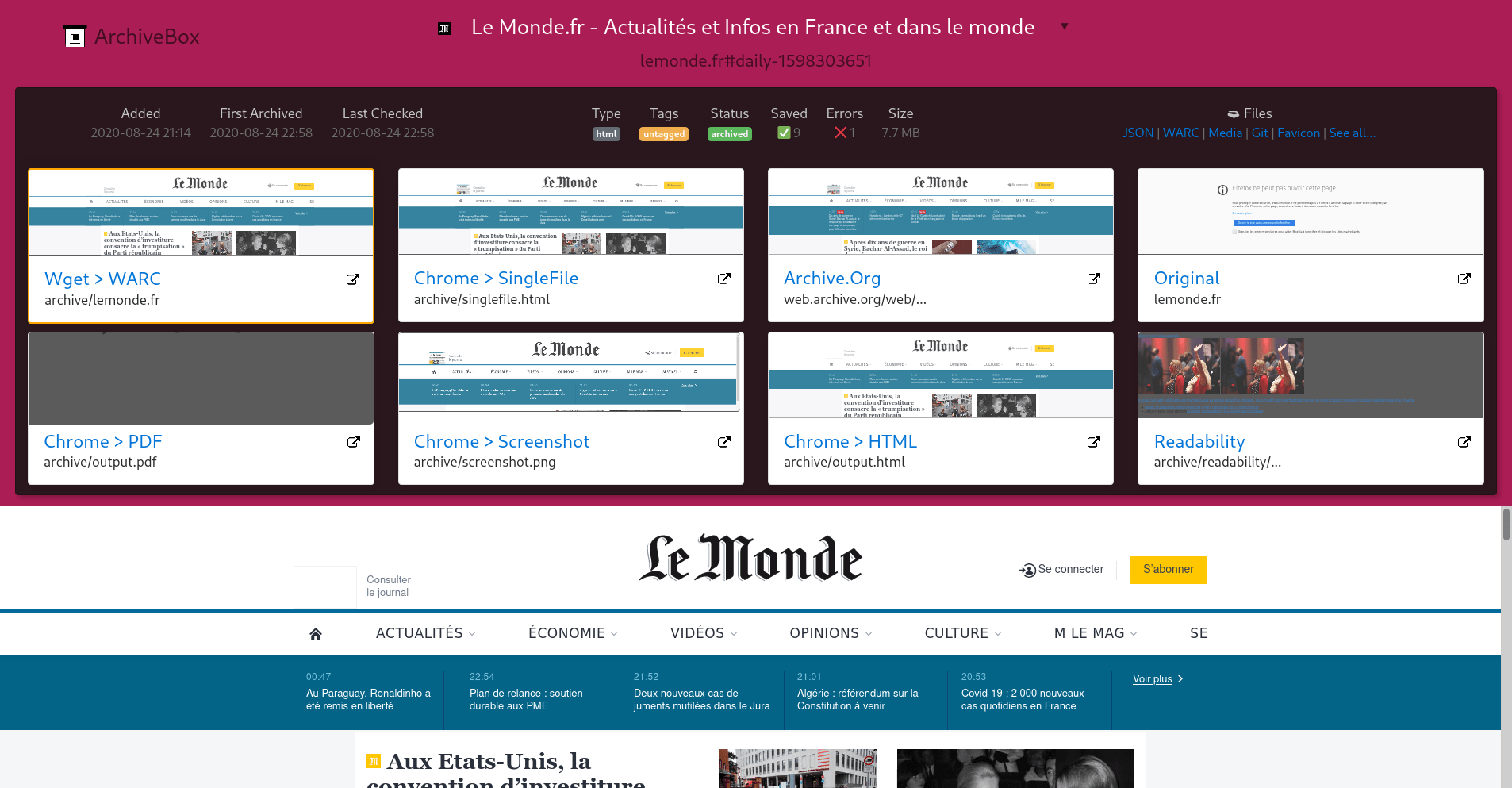
Archivebox est un logiciel à auto-héberger permettant d’archiver des pages web grâce à une large collection d’outils d’archivage.
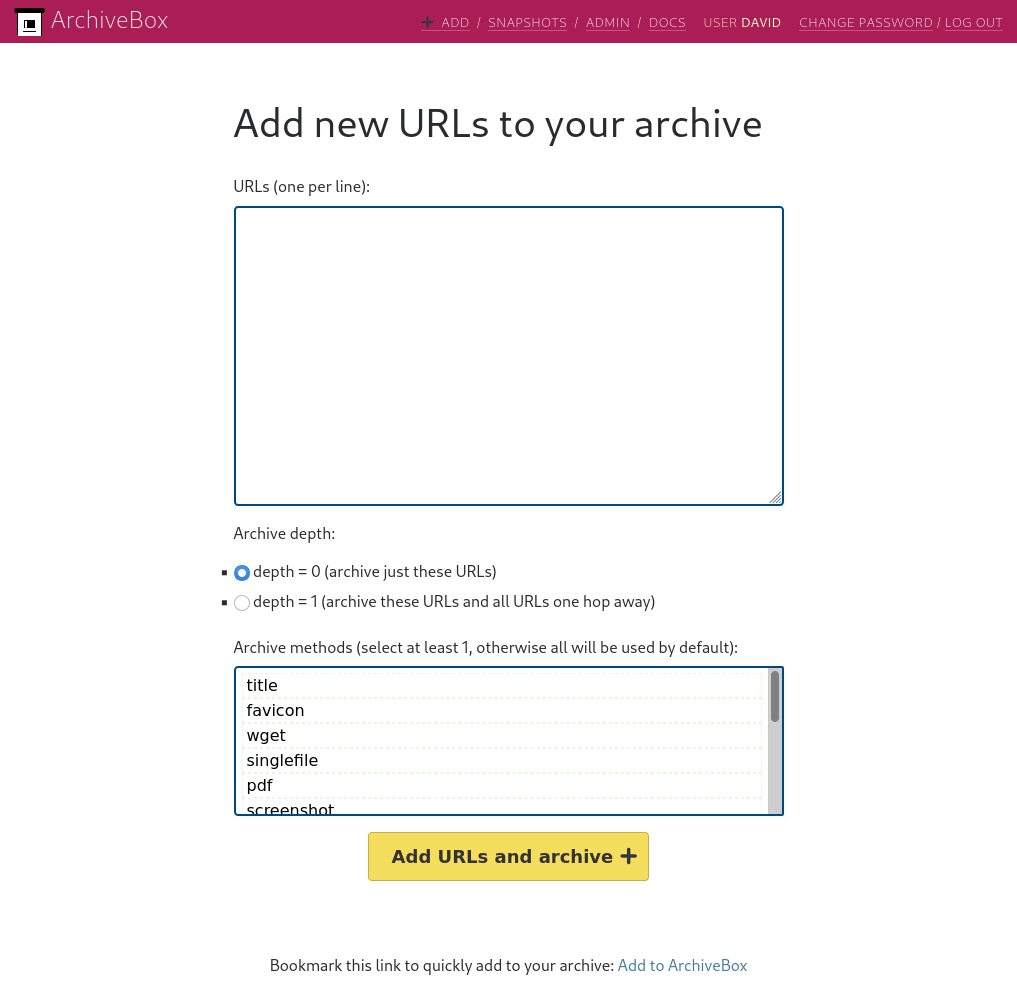
L’archivage d’une URL avec archivebox peut se faire avec les méthodes suivantes :
- Téléchargement avec wget
- Téléchargement d’un fichier html unique avec SingleFile
- Téléchargement en PDF
- Capture d’écran
- Téléchargement du html avec Chrome Headless
- Extraction du texte avec readability
- Envoi vers archive.org
- Téléchargement des médias avec youtube-dl
Archivebox est une librairie développé en Python avec le framework Django et dont l’intégralité du code source est disponible sur Github.
Ce logiciel est plus complexe que les deux précédents, mais c’est le plus personnalisable et celui proposant le plus de fonctionnalités.
Installation
La méthode d’installation recommandée utilise docker-compose.
Il faut tout d’abord préparer le dossier qui contiendra l’archive :
mkdir archivebox
cd archivebox
docker pull nikisweeting/archivebox:latest
docker-compose run archivebox init
docker-compose run archivebox manage createsuperuser
Voici un fichier docker-compose d’exemple (changez DATA_FOLDER par l’emplacement de l’archive créée précédemment) :
---
version: "3.7"
services:
archivebox:
image: nikisweeting/archivebox:latest
command: server 0.0.0.0:8080
stdin_open: true
tty: true
container_name: archivebox
environment:
- USE_COLOR=True
- SHOW_PROGRESS=False
- TIMEOUT=120
- MEDIA_TIMEOUT=300
volumes:
- /DATA_FOLDER:/data
ports:
- 8080:8080
restart: unless-stopped
Lancez le conteneur :
docker-compose up -d
L’interface web d’Archivebox sera accessible sur le port 8080 de votre serveur.
Utilisation
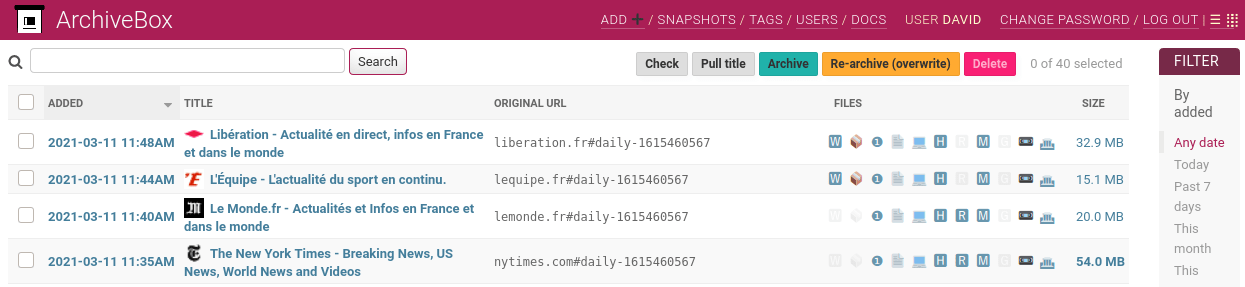
Archivebox est accessible via une interface web qui listera toutes les archives, mais est aussi contrôlable via un utilitaire en ligne de commande.
Ajout d’une URL à l’archive via la ligne de commande :
docker-compose run archivebox add 'https://example.com'
# si vous voulez aussi archiver le contenu des liens présents sur la page
docker-compose run archivebox --depth=1 add 'https://example.com'
Il est aussi possible d’ajouter des liens directement depuis l’interface web.
Une limitation importante d’Archivebox est l’incapacité d’archiver deux fois la même URL.
Si vous voulez archivez régulièrement la page d’accueil d’un média pour créer une frise chronologique des différents titres qui ont fait l’actualité, il faudra ruser en ajoutant du texte invalide à l’URL.
# Exemple : première extraction du site example.com
docker-compose run archivebox add 'https://example.com#1'
# Plus tard, deuxième extraction du site example.com
docker-compose run archivebox add 'https://example.com#2'
Personnellement, j’ajoute le timestamp actuel à l’URL, par exemple https://lemonde.fr#daily-1615460567.
Pour plus d’informations, vous pouvez regarder ce rapport de bug : https://github.com/ArchiveBox/ArchiveBox/issues/179
Le commande add d’archivebox permet aussi d’extraire les liens d’un fichier. Par exemple, pour archiver toutes les URLs contenues dans un fichier texte :
docker-compose run archivebox add < 'URLs.txt'
Une autre fonctionnalité est la possibilité d’organiser des extractions planifiées avec la commande schedule. L’option --every accepte les valeurs hour/day/month/year ou une valeur au format cron comme "0 0 * * *".
Cette fonction de schedule n’ajoutera que les liens qui n’ont jamais été archivés. Cela peut être utile pour surveiller un flux RSS ou une liste de favoris. À noter que c’est l’option depth=1 qui permet l’extraction des URLs contenues dans le fichier et pas uniquement le fichier en lui même.
docker-compose run archivebox schedule --depth=1 --every=day 'URLs.txt'
Il est possible d’afficher les extractions planifiées avec l’option --show et de toutes les supprimer avec --clear.
docker-compose run archivebox schedule --show
docker-compose run archivebox schedule --clear
Même si Archivebox est un logiciel que j’apprécie beaucoup, tout n’est pas parfait.
Certaines opérations simples comme lister des archives via l’interface web sont très longues et peuvent occasionner des plantages de l’application. De plus, le logiciel souffre d’un certain manque de finition (la distinction fichier/URL dans les fonctions d’ajout et leur gestion est assez opaque) et certaines fonctionnalités comme l’usage d’archivebox en ligne de commande ou l’interfaçage avec Python sont mal documentées : on retrouve dans la documentation officielle beaucoup de pages dupliquées et d’informations incomplètes.
C’est un logiciel qui a malgré tout énormément de potentiel.
Conclusion
Ces trois logiciels sont assez complémentaires, ils peuvent tous trois archiver du contenu du web mais avec des approches différentes.
Wallabag sera plutôt pour les utilisateurs intéressés par la sauvegarde de contenu à des fins de relecture, là où Conifer ravira ceux qui préfèrent archiver le contenu dans sa forme la plus originale possible (à la Wayback Machine), au prix d’une relecture plus difficile.
Archivebox de son côté essaye de conserver le plus possible en archivant les pages avec un large panel d’outils. Cela se fait au prix d’une complexité plus importante et une prise en main moins immédiate.
Les trois logiciels que j’ai présenté ne sont pas destinés à archiver des vidéos ou des fichiers audio. Si c’est votre usage (par exemple pour archiver du contenu provenant d’un hébergeur de vidéos), vous pouvez regarder du côté de youtube-dl. Comme son nom ne l’indique pas, youtube-dl est compatible avec un grand nombre de services comme youtube, dailymotion, twitch, vimeo ou encore les sites d’arte ou francetv.
Une remarque, un commentaire ? Réagissez sur Mastodon !
>> Home